Self-Citation Analysis¶
Citation counts and h-index values are useful summary statistics, but they can
be blurred by excessive self-citation. paperscraper helps inspect this effect
with paper-level and author-level self-citation and self-reference analyses.
The citation workflow uses Semantic Scholar paper, citation, and reference metadata. It can run without authentication, but larger analyses should use a Semantic Scholar API key:
Self-References of a Paper¶
Start from a paper DOI or Semantic Scholar paper ID. Self-references ask: among the papers referenced by this paper, how many include one of the paper's own authors?
>>> from paperscraper.citations import self_references_paper
>>> doi = "10.1038/s41586-023-06600-9"
>>> self_references = self_references_paper(doi)
>>> self_references.num_references
33
>>> self_references.reference_score
5.05
The score is the mean self-reference percentage across the authors of the paper. The per-author values are available directly:
>>> self_references.self_references
{
"Abhishek Sharma": 3.03,
"Dániel Czégel": 0.0,
"Michael Lachmann": 0.0,
"C. Kempes": 0.0,
"S. I. Walker": 6.06,
"Leroy Cronin": 21.21,
}
Here, 21.21 means that 21.21% of the paper's references include Leroy Cronin
as an author.
Self-Citations of a Paper¶
The same idea can be turned around. Instead of looking at the references made by the paper, self-citations look at later papers that cite it and ask how often those citing papers include one of the original paper's authors.
>>> from paperscraper.citations import self_citations_paper
>>> self_citations = self_citations_paper(doi)
>>> self_citations.num_citations
141
>>> self_citations.citation_score
3.192
>>> self_citations.self_citations
{
"Abhishek Sharma": 3.55,
"Dániel Czégel": 0.71,
"Michael Lachmann": 1.42,
"C. Kempes": 3.55,
"S. I. Walker": 4.96,
"Leroy Cronin": 4.96,
}
Here, 4.96 means that 4.96% of the papers citing the focal paper include
Leroy Cronin as an author.
Both self_references_paper and self_citations_paper accept either one
DOI/Semantic Scholar paper ID or a list. A single input returns one result
object; a list returns a list of result objects.
Researcher-Level Tendencies¶
Now imagine doing this for every paper of an author. This gives a researcher- level tendency for self-references and self-citations, aggregated over that author's publication record.
For author-level workflows, use Researcher. Full author analyses can take
longer for large publication lists, so this example limits the run to one paper.
>>> from paperscraper.citations.entity import Researcher
>>> researcher = Researcher("2289839817")
>>> researcher.ssids = ["2c1edb95c07643a834c9d4f8f2acedfecfe894de"]
>>> _ = researcher.self_citations()
>>> result = researcher.self_references()
>>> result.name
"K. Wijk"
>>> result.self_citation_ratio
0.0
>>> result.self_reference_ratio
4.65
>>> result.num_citations
10
>>> result.num_references
43
>>> result.self_references
{"Diff-SPORT: Diffusion-based Sensor Placement Optimization and Reconstruction of Turbulent flows in urban environments": 4.65}
>>> result
ResearcherResult(
name="K. Wijk",
self_reference_ratio=4.65,
self_citation_ratio=0.0,
num_references=43,
num_citations=10,
self_references={
"Diff-SPORT: Diffusion-based Sensor Placement Optimization and Reconstruction of Turbulent flows in urban environments": 4.65,
},
self_citations={
"Diff-SPORT: Diffusion-based Sensor Placement Optimization and Reconstruction of Turbulent flows in urban environments": 0.0,
},
ssaid=2289839817,
orcid=None,
)
The example above uses Klaas Wijk's Semantic Scholar author profile and pins the analysis to one paper to keep the runtime short.
Researcher-per-Discipline Self-Link Analysis¶
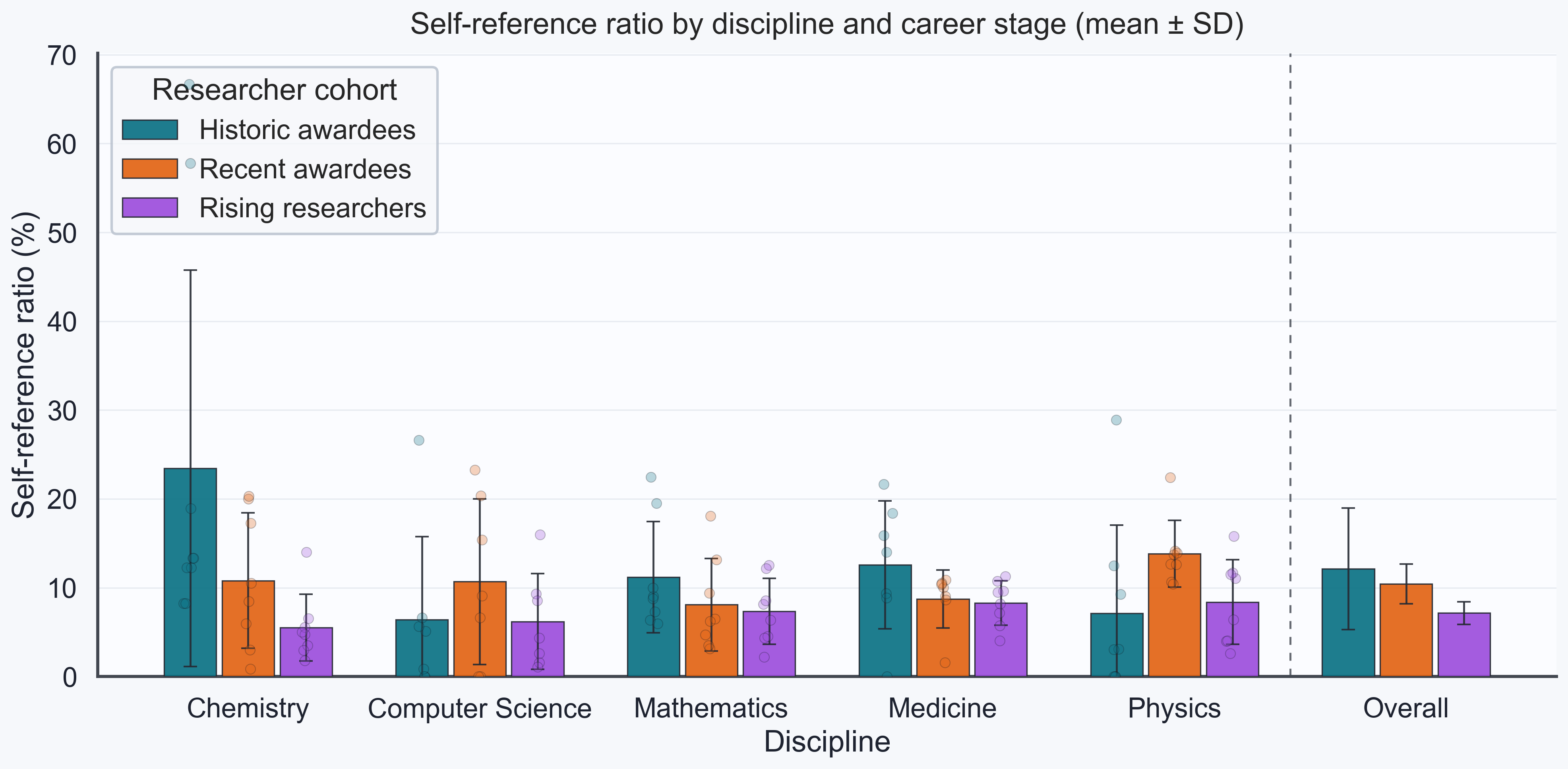
The plots below summarize a small benchmark analysis of self-links grouped by
discipline and researcher category. The processed table uses three categories:
historic awardees (PastSenior) for Nobel Prize, Fields Medal, and Turing
Award winners before 2000, represented here by 1993-1998 laureates; recent
awardees (TodaySenior) for comparable senior prize winners since 2018; and
rising researchers (TodayJunior) for 2025 rising-star researchers selected as
plausible future candidates for such prizes.
The plots show mean ± standard deviation by discipline and category. Individual
researchers are overlaid as points, and the separated Overall block averages
the five discipline-level means for each researcher cohort.
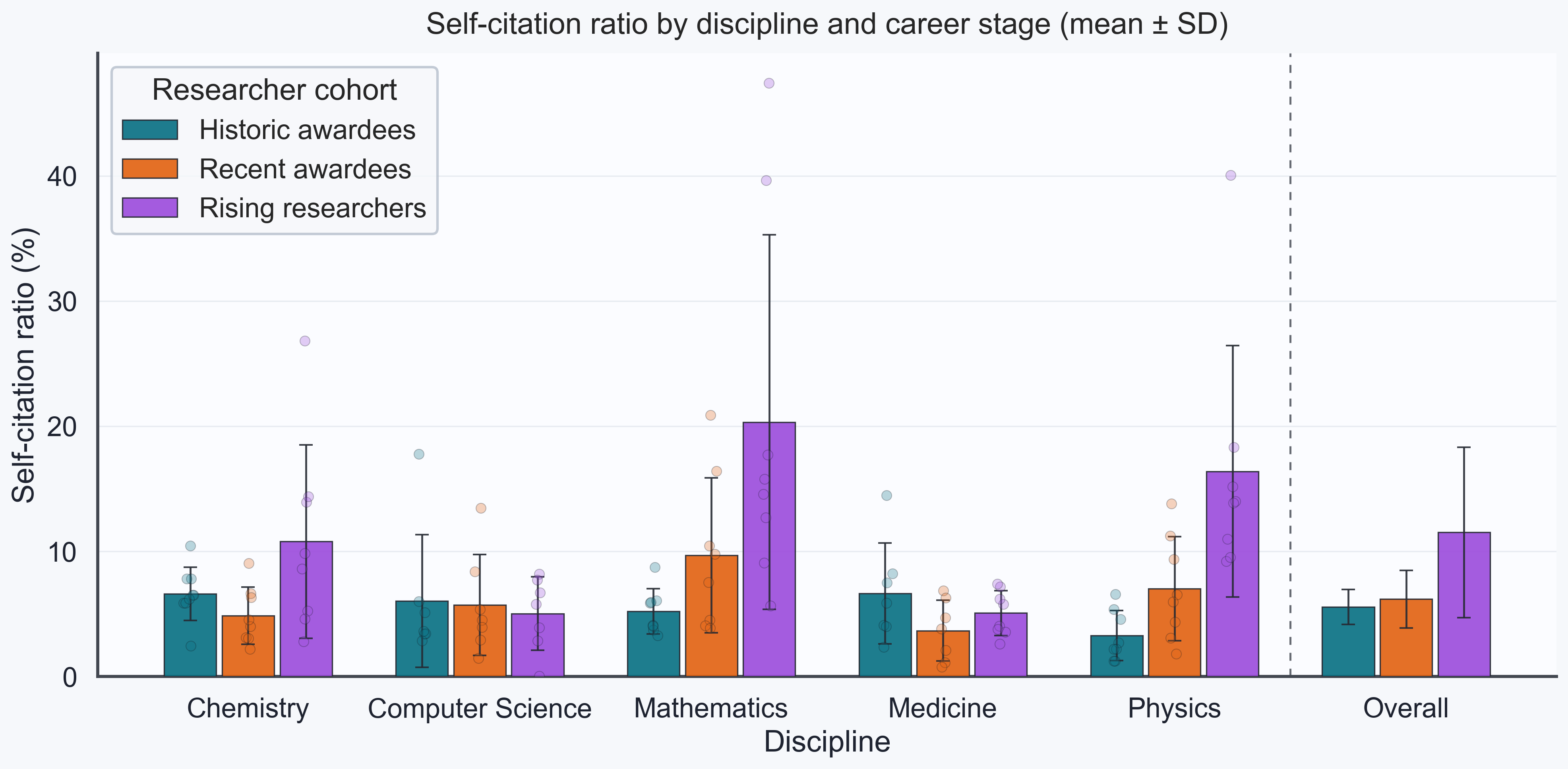
The strongest statistically supported signal is in self-citations rather than
self-references. A discipline-stratified permutation test finds that
rising researchers have higher self-citation ratios than the other two groups by
5.79 percentage points (p < 0.0001, Benjamini-Hochberg q = 0.0010).
Pairwise Mann-Whitney checks show the same pattern against both historic
awardees (p = 0.0007) and recent awardees (p = 0.0044).
Here, "percentage points" means an absolute difference in percentages: a change
from 5% to 10% is +5 percentage points. The q value is the p-value after
Benjamini-Hochberg correction across the tested career-stage and discipline
contrasts. "Discipline-stratified" means that the class labels are shuffled only
within each discipline, so the junior effect is not merely a consequence of one
discipline having both more junior researchers and a different baseline
self-citation rate.
Across disciplines, mathematics has the clearest effect: after stratifying by
career-stage group, mathematicians have higher self-citation ratios than the
other disciplines by 4.91 percentage points (p = 0.0020, q = 0.0245).
The visually plausible self-reference trends are weaker. Rising researchers
have lower, not higher, self-reference ratios by 4.36
percentage points, but this is only nominal after correction (p = 0.0121,
q = 0.0724). Pooling self-citations and self-references into a combined
standardized score over the two rates does not produce a robust class or
discipline result.
These results should be read as associations, not causal claims. The higher rising-researcher self-citation ratio may partly reflect shorter citation windows: younger papers have had less time to accumulate independent citations, so early citations may contain a larger fraction of follow-up work from the same authors. The aggregate benchmark controls for discipline composition in the tests above, but it does not model paper age, citation-window length, or field-specific citation velocity.
Unified Interface¶
Use SelfLinkClient when you want self-citations and self-references through
one object. Paper inputs can be DOIs, Semantic Scholar paper IDs, or titles; use
mode when you want to disambiguate.
>>> from paperscraper.citations import SelfLinkClient
>>> paper_client = SelfLinkClient("10.1038/s41586-023-06600-9", mode="paper")
>>> paper_client.extract()
>>> paper_client.get_result()
PaperResult(
ssid="10.1038/s41586-023-06600-9",
title="Assembly theory explains and quantifies selection and evolution",
num_citations=141,
self_citations={
"Abhishek Sharma": 3.55,
"Dániel Czégel": 0.71,
"Michael Lachmann": 1.42,
"C. Kempes": 3.55,
"S. I. Walker": 4.96,
"Leroy Cronin": 4.96,
},
citation_score=3.192,
num_references=33,
self_references={
"Abhishek Sharma": 3.03,
"Dániel Czégel": 0.0,
"Michael Lachmann": 0.0,
"C. Kempes": 0.0,
"S. I. Walker": 6.06,
"Leroy Cronin": 21.21,
},
reference_score=5.05,
)
SelfLinkClient(..., mode="author") wraps the same Researcher object used
above and returns a ResearcherResult. Use Researcher directly when you want
to limit or inspect the paper list before running the analysis; the example below
does the same pinning through the client for compact output.
>>> author_client = SelfLinkClient("2289839817", mode="author")
>>> author_client.object.ssids = ["2c1edb95c07643a834c9d4f8f2acedfecfe894de"]
>>> author_client.extract()
>>> author_client.get_result()
ResearcherResult(
name="K. Wijk",
self_reference_ratio=4.65,
self_citation_ratio=0.0,
num_references=43,
num_citations=10,
self_references={
"Diff-SPORT: Diffusion-based Sensor Placement Optimization and Reconstruction of Turbulent flows in urban environments": 4.65,
},
self_citations={
"Diff-SPORT: Diffusion-based Sensor Placement Optimization and Reconstruction of Turbulent flows in urban environments": 0.0,
},
ssaid=2289839817,
orcid=None,
)